…
Along the design research, we are going through many different types of references that we don’t necessarily post or document on the blog. We usually only post about the ones that we consider relevant to the research process, which doesn’t mean the other ones are not interesting. We’ve just decided not to dig deeper into them at some point, or to keep some of them for later.
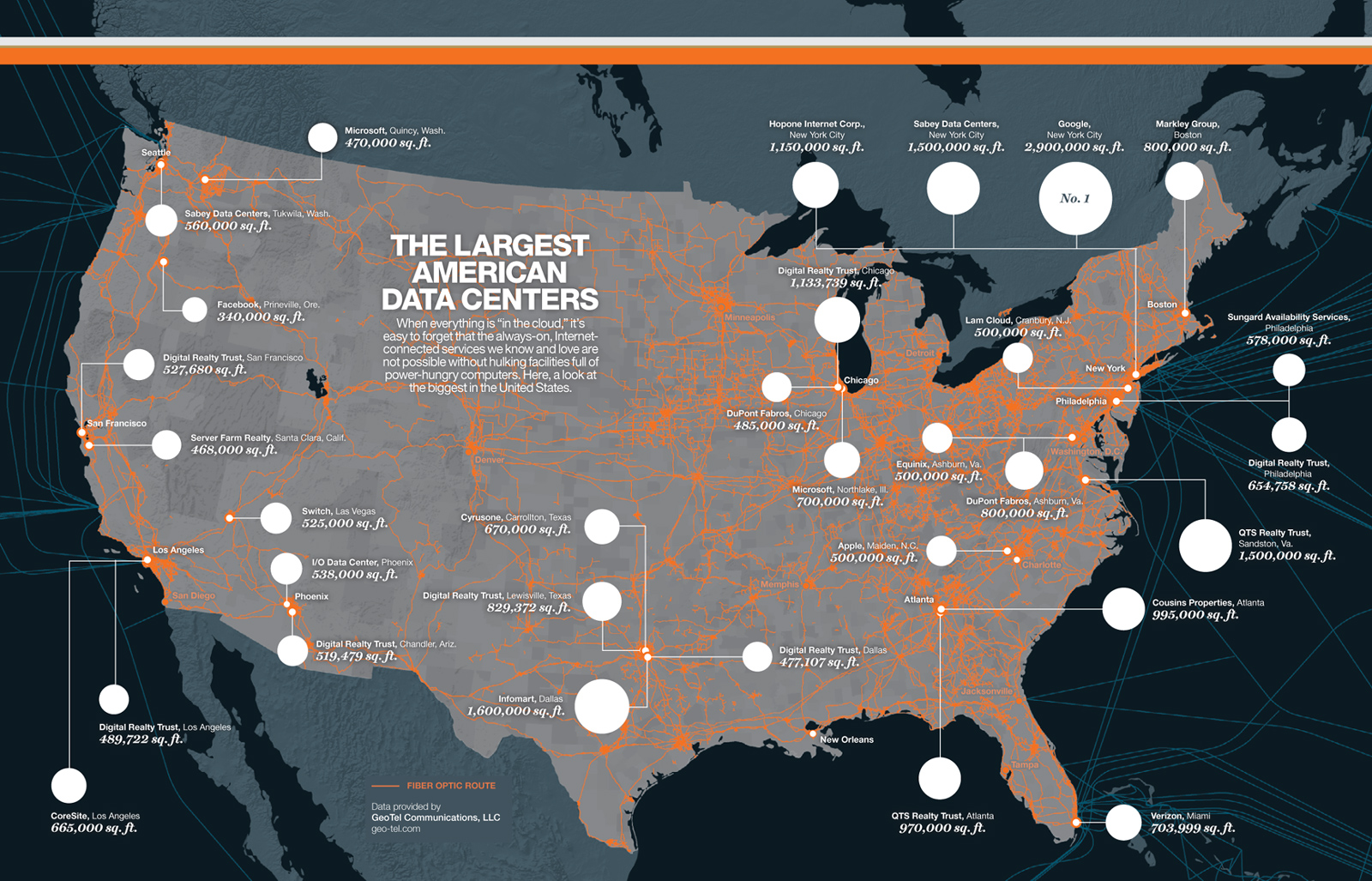
Yet, this is a consistent amount of survey that we are leaving on the side of the road and that could possibly be useful for similar or later researches. At least a good starting point… That’s why we’ve created this i&ic_designresearch tag on Pinboard.
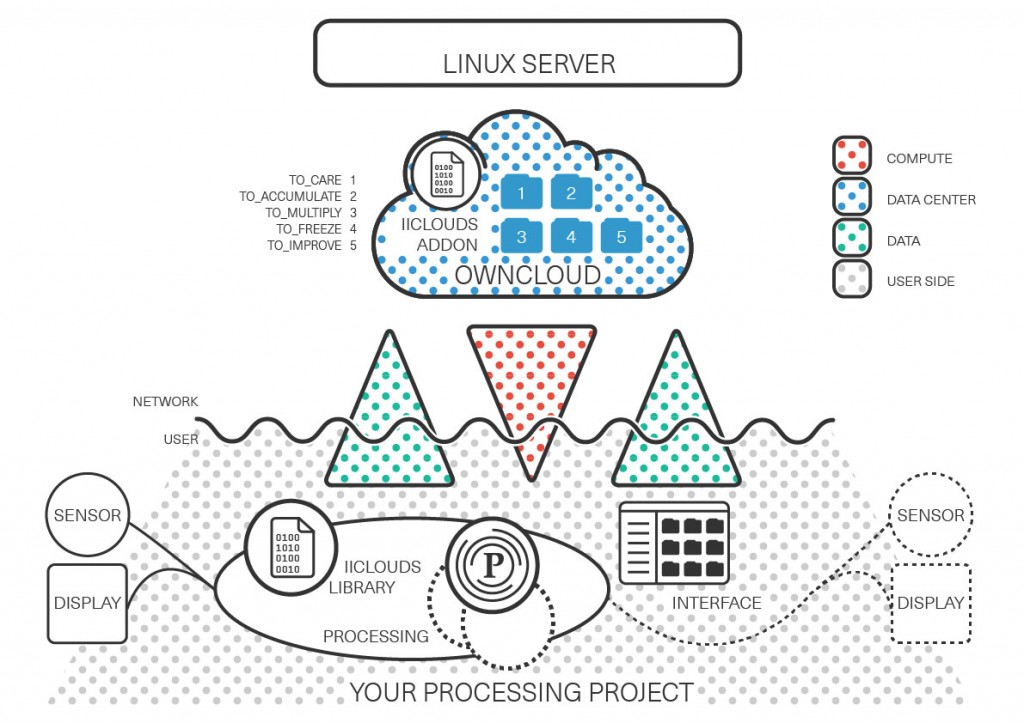
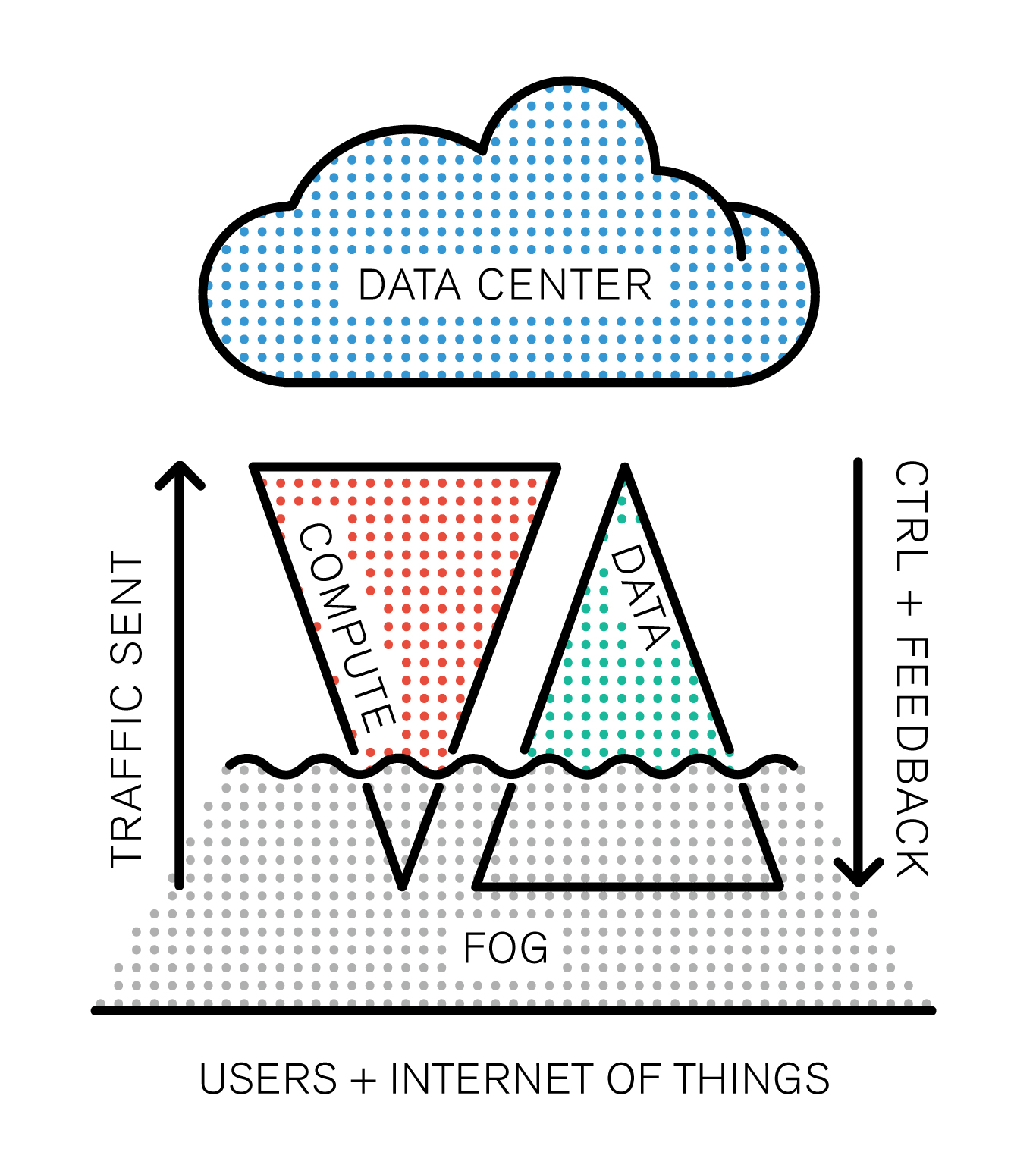
Interestingly, some new thematics emerged along the way within these links, like for example on the technological branch, the combination of personal cloud based services, peer to peer protocols and blockchains that were not on the radar when we started our research.