We’re entering the final straight of the research project Inhabiting and Interfacing the Cloud(s) and we can give at this point a first glimpse of the four design artifacts we are working on at the moment. They will constitute the main outcomes of our joint experimental effort (ECAL, HEAD, EPFL-ECAL Lab) and a kind of “personal cloud kit” (explained below). These creations will be accompanied by two books: one will present the results of the ethnographic research about “the cloud”, the other will present the design research process and its results – both in pod/pdf.
We already pointed out in the recent post “Updated Design Scenario” where we were heading. Since then, the different projects were better identified and started to get shaped. Some got eliminated. Prototyping and further technical tests are running in parallel at the moment.
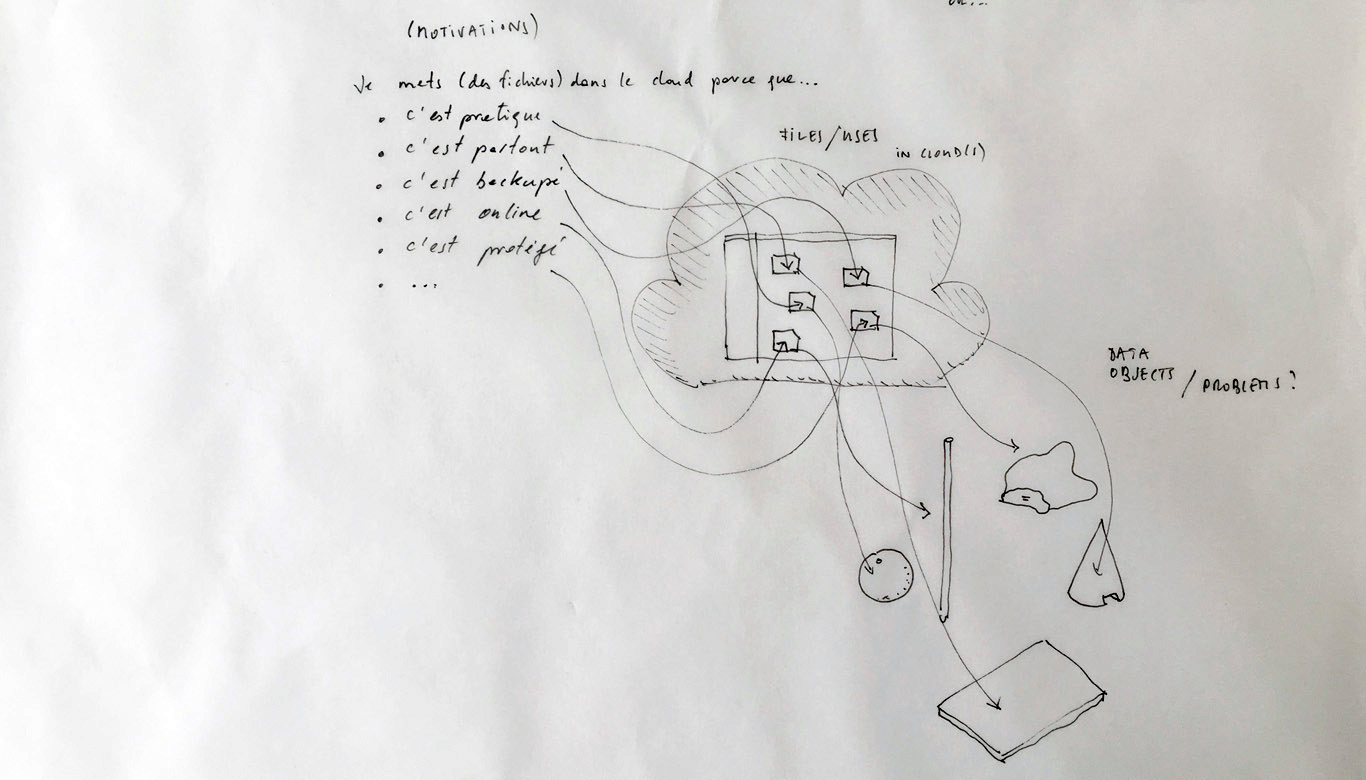
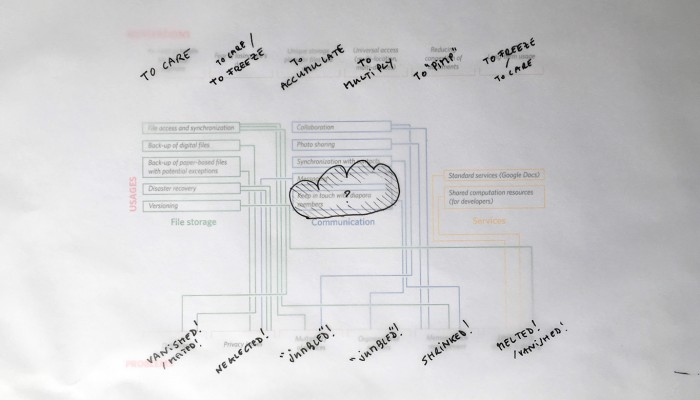
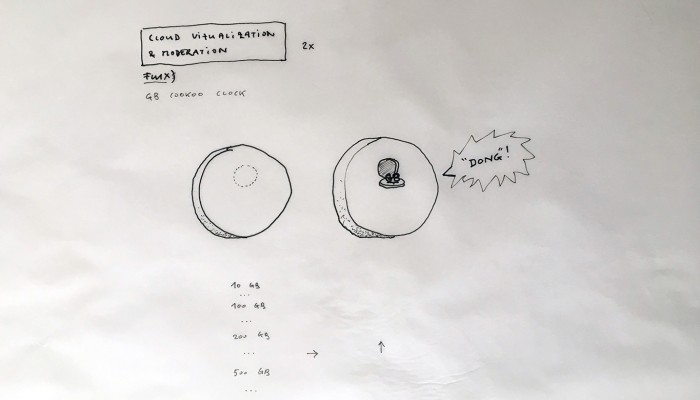
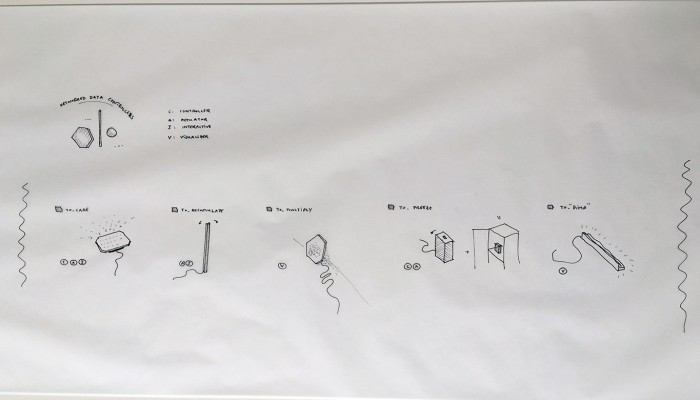
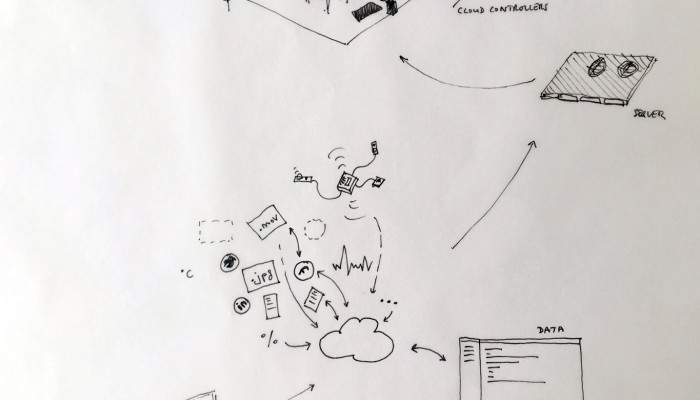
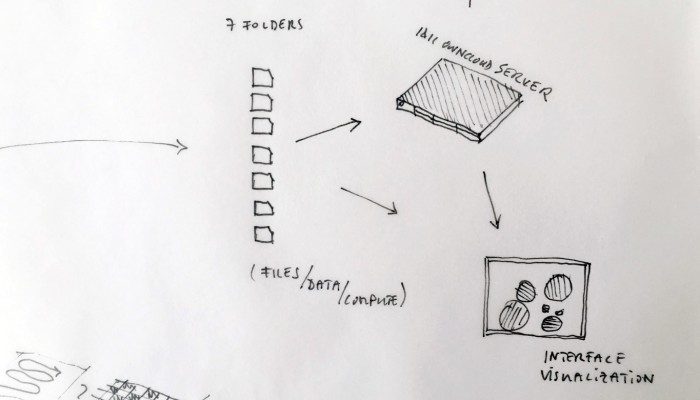
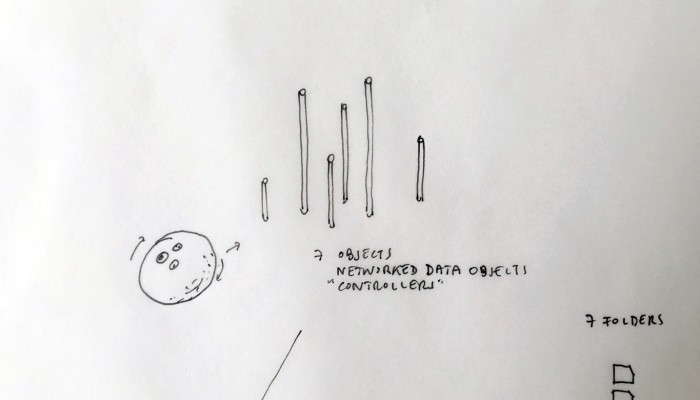
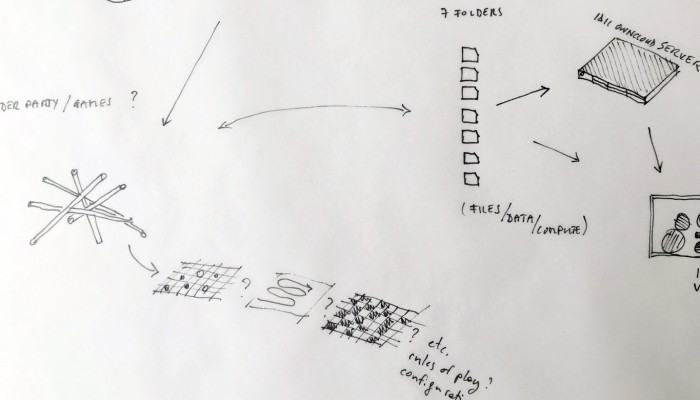
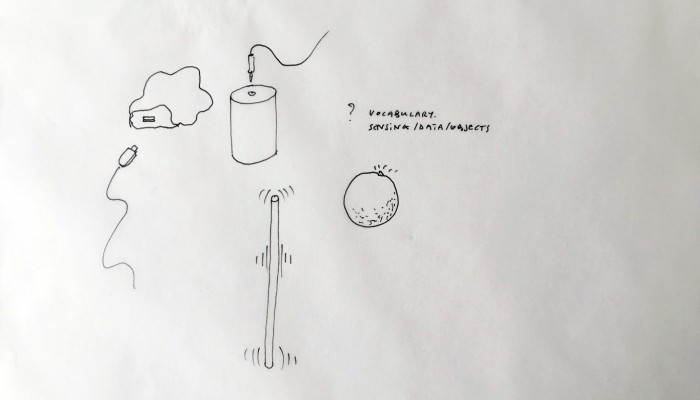
From the original “final scenario” sketch to …
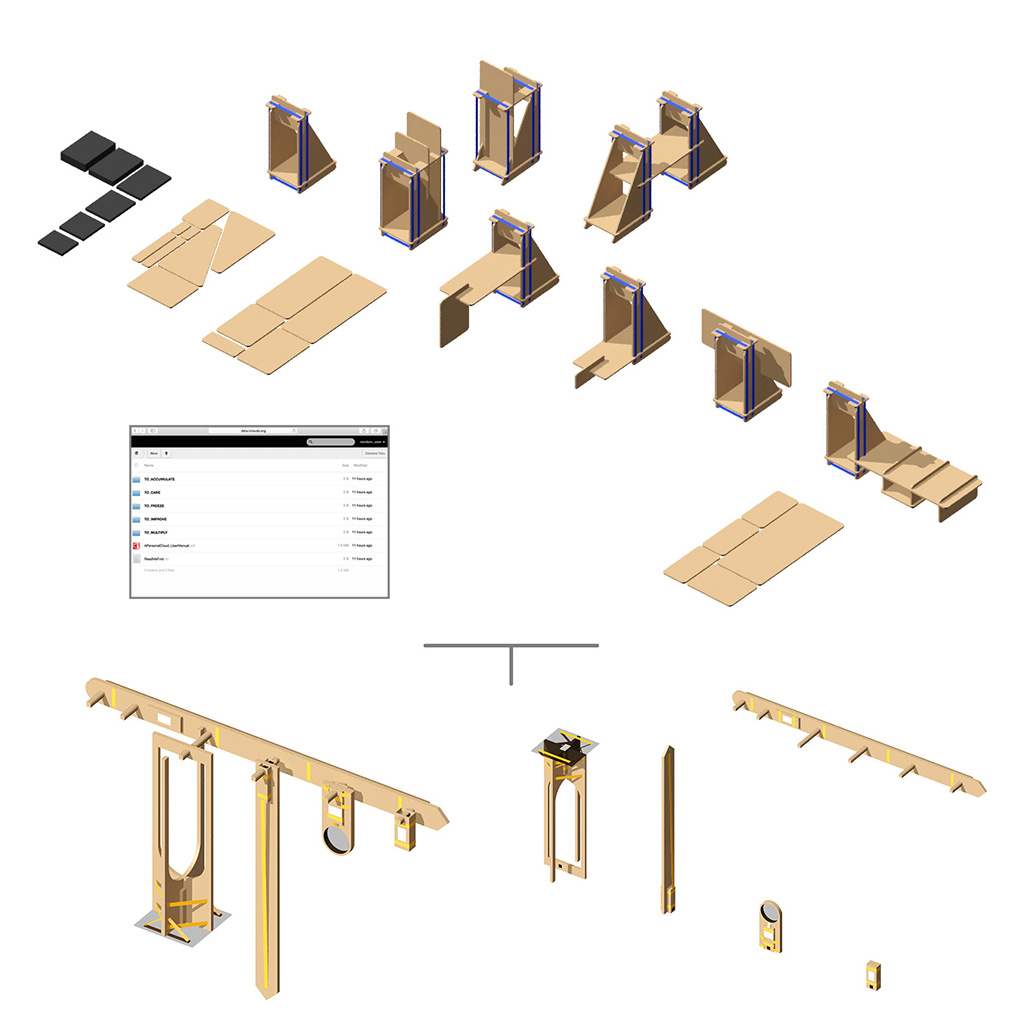
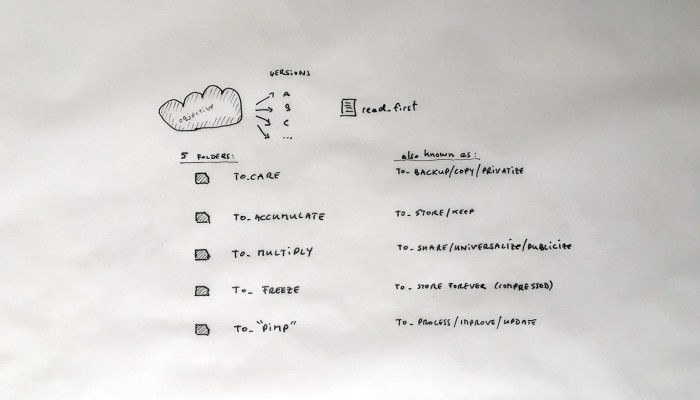
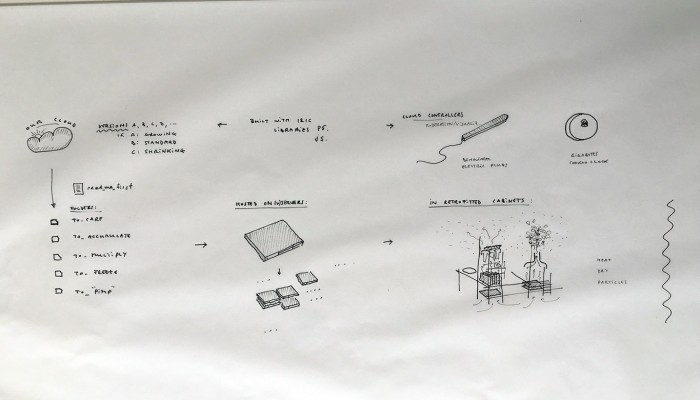
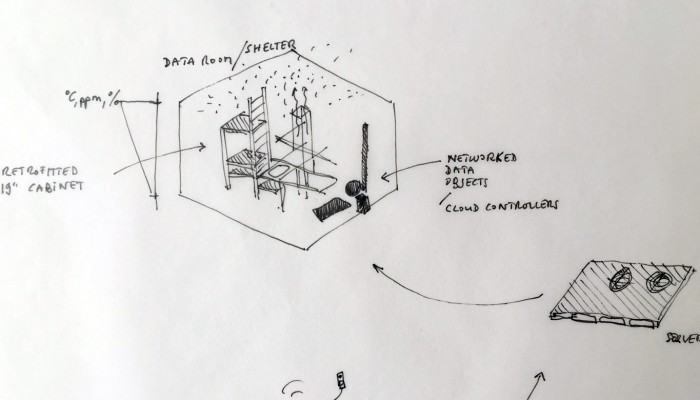
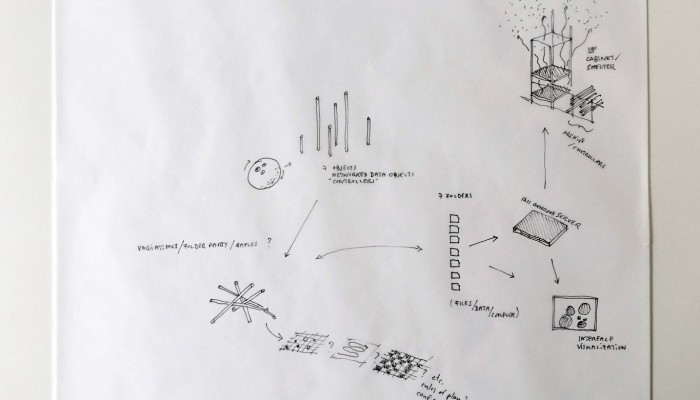
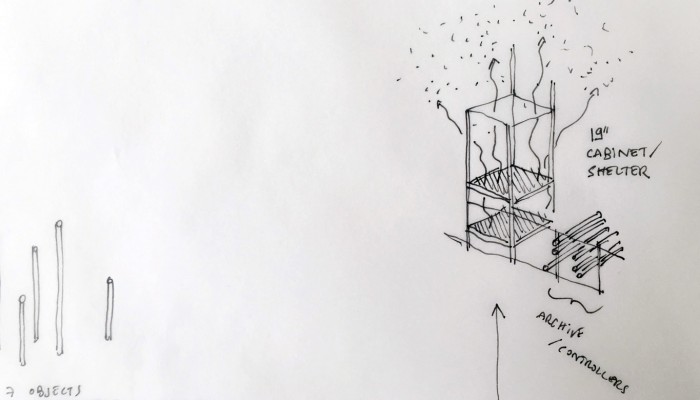
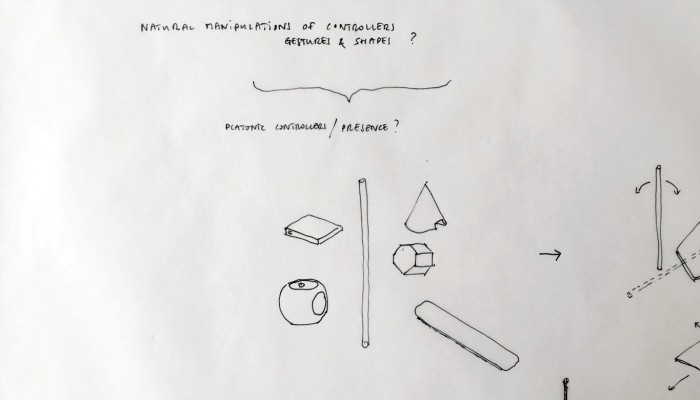
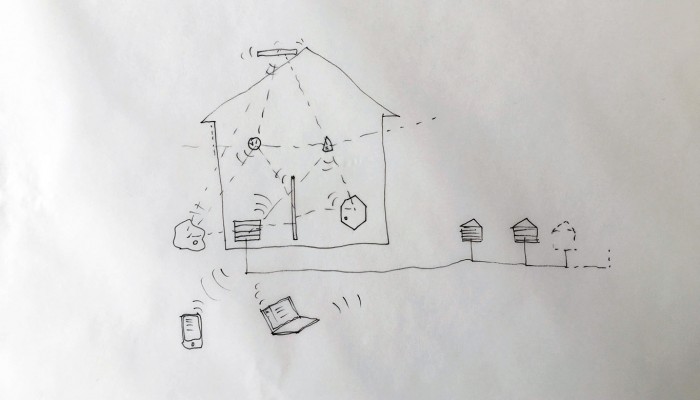
… a “Personal Cloud Kit”, composed of various physical and digital modular artifacts.
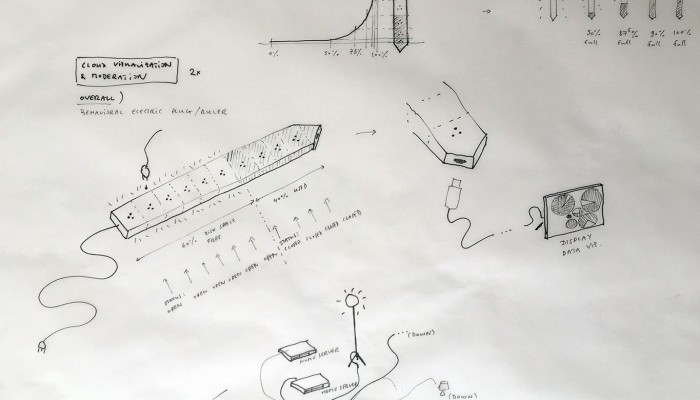
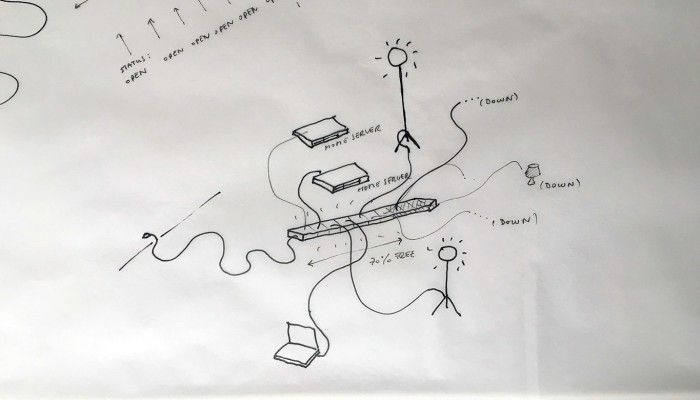
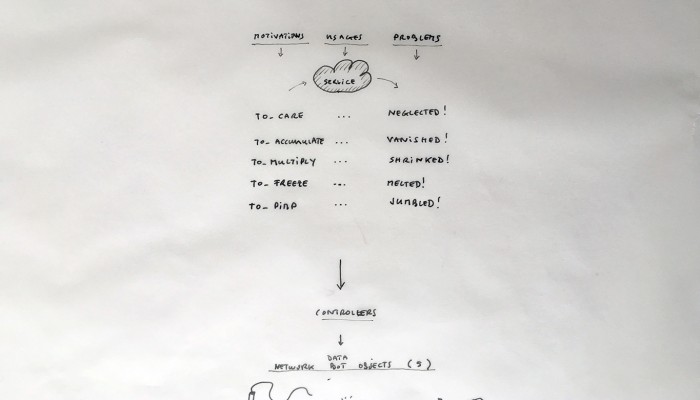
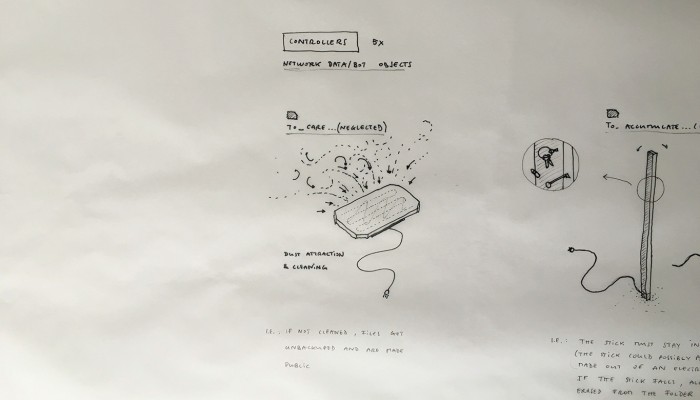
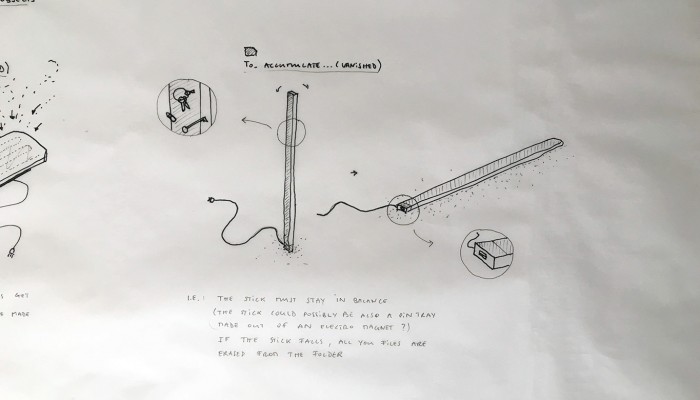
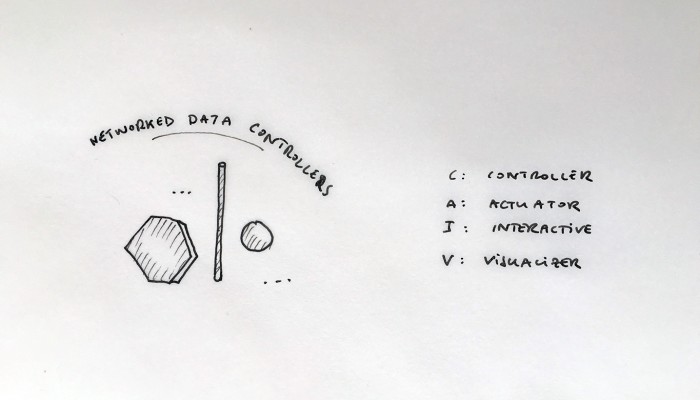
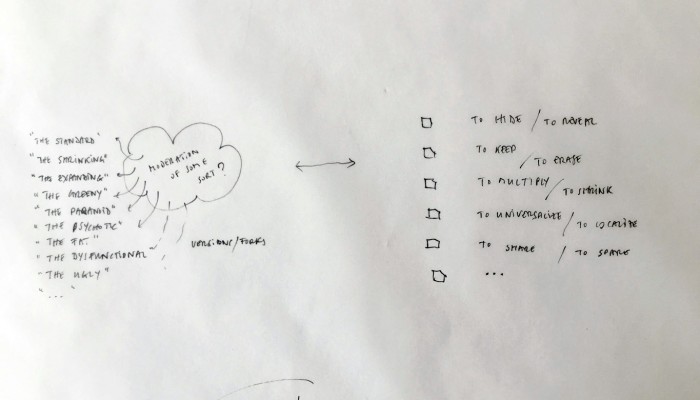
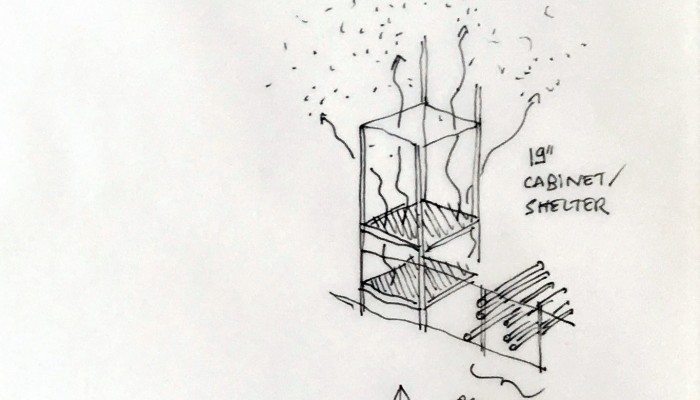
What emerged reinforced from the main design scenario is that we seek to deliver four artifacts (some physical, some digital, some combined) which themselves will constitute the building blocks of what we’ll call “A Personal Cloud Kit”. All four parts of this kit will be openly accessible on a dedicated website (e.g. in a similar way to what OpenDesk is doing).
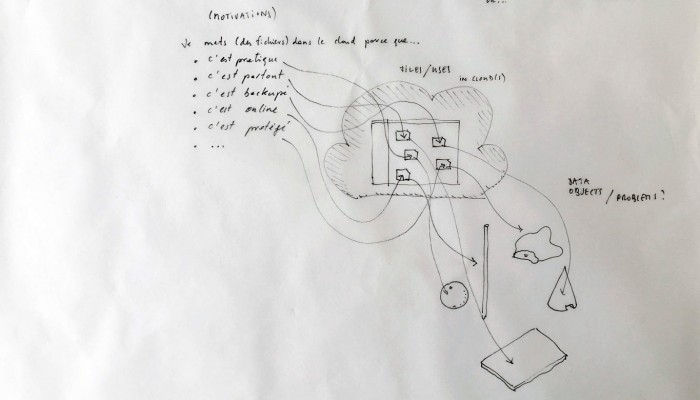
The purpose of this “home kit” is to empower designers, makers and citizens at large who would be interested to start develop their own cloud projects, manage or interact with their data or even to set up small scale personal data centers at their places (homes, offices, garages …)