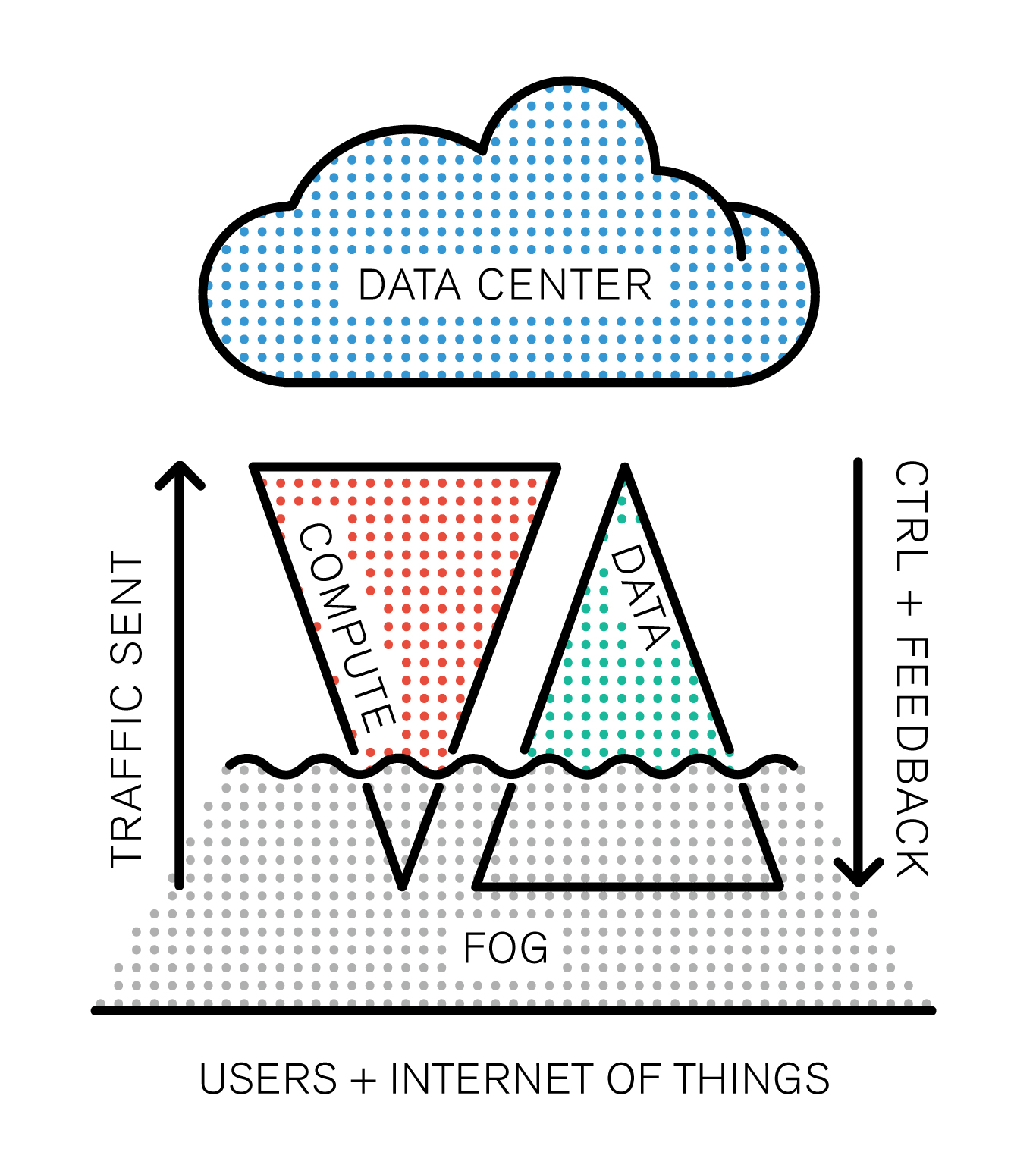
The Internet of Things is emerging as a model, and the network routing all the IoT data to the cloud is at risk of getting clogged up. “Fog is about distributing enough intelligence out at the edge to calm the torrent of data, and change it from raw data over to real information that has value and gets forwarded up to the cloud.” Todd Baker, head of Cisco‘s IOx framework says. Fog Computing, which is somehow different from Edge Computing (we didn’t quite get how) is definitely a new business opportunity for the company who’s challenge is to package converged infrastructure services as products.
However, one interesting aspect of this new buzzword is that it adds up something new to the existing model: after all, cloud computing is based on the old client-server model, except the cloud is distributed by its nature (ahem, even though data is centralized). That’s the big difference. There’s a basic rule that resumes the IT’s industry race towards new solutions: Moore’s law. The industry’s three building blocks are: storage, computing and network. As computing power doubles every 18 months, storage follows closely (its exponential curve is almost similar). However, if we graph network growth it appears to follow a straight line.
Network capacity is a scarce resource, and it’s not going to change any time soon: it’s the backbone of the infrastructure, built piece by piece with colossal amounts of cables, routers and fiber optics. This problematic forces the industry to find disruptive solutions, and the paradigm arising from the clash between these growth rates now has a name: Data gravity.
