A few images for a brief history (of computing) time
Note: a aet of images I’ll need for a short introduction to the project.
From mainframe computers to cloud computing, through personal computer and all other initiatives that tried to curve “the way computers go” and provide access to tools to people who were not necessarily computer savvy. Under this perspective (“access to tools”), cloud computing is a new paradigm that takes us away from that of the personal computer. To the point that it brings us back to the time of the mainframe computer (no-access or difficult access to tools)?
If we consider how far the personal computer, combined with the more recent Internet, has changed the ways we interact, work and live, we should certainly pay attention to this new paradigm that is coming and probably work hard to make it “accessible”.

A very short history pdf in 14 images.
Reblog > Decentralizing the Cloud: How Can Small Data Centers Cooperate?
Note: while reading last Autumn newsletter from our scientific committee partner Ecocloud (EPFL), among the many interesting papers the center is publishing, I stumbled upon this one written by researchers Hao Zhuang, Rameez Rahman, and Prof. Karl Aberer. It surprised me how their technological goals linked to decentralization seem to question similar issues as our design ones (decentralization, small and networked data centers, privacy, peer to peer models, etc.)! Yet not in such a small size as ours, which rather look toward the “personal/small” and “maker community” size. They are rather investigating “regional” data centers, which is considered small when you start talking about data centers.
Towards a new paradigm: Fog Computing
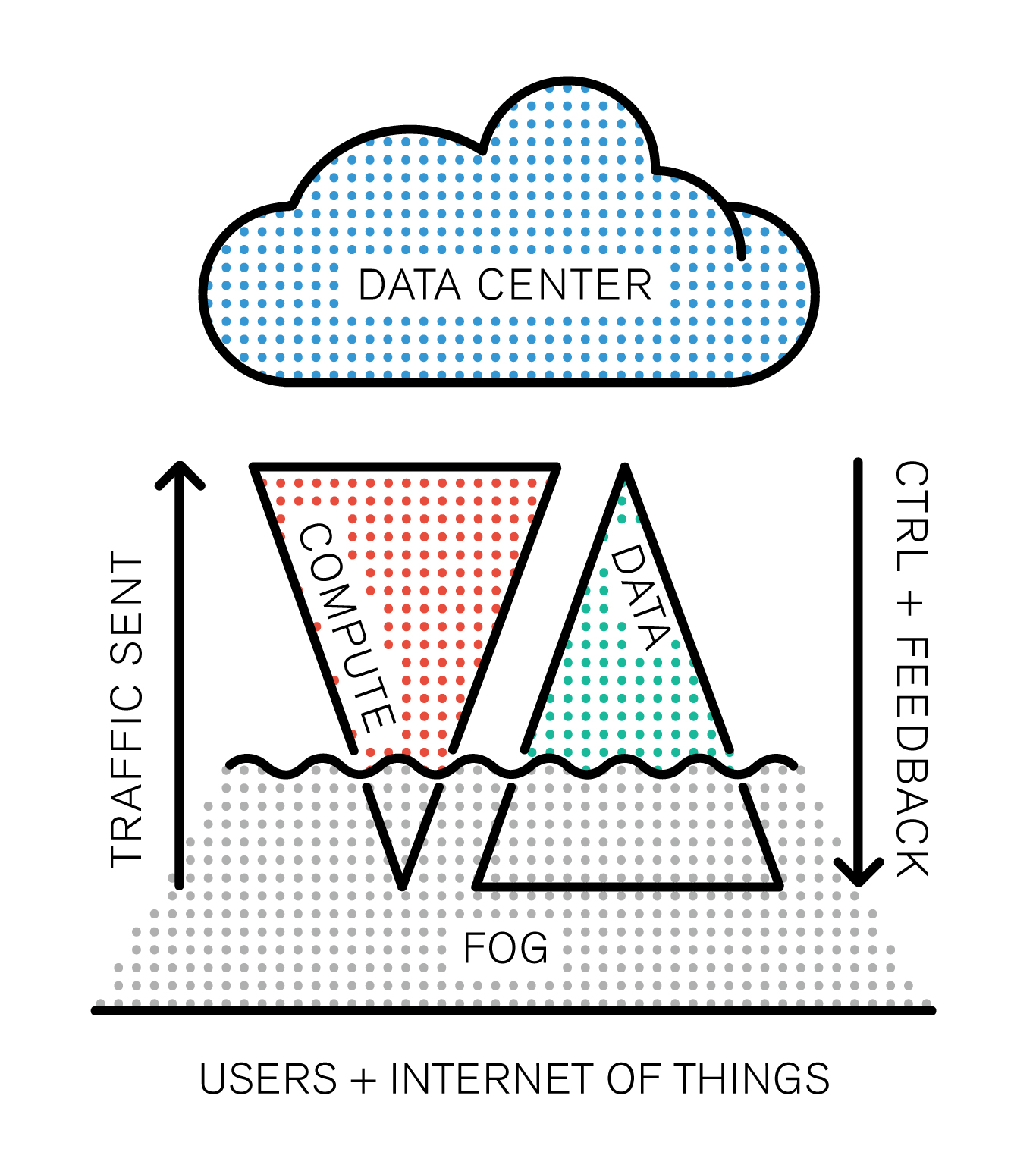
The Internet of Things is emerging as a model, and the network routing all the IoT data to the cloud is at risk of getting clogged up. “Fog is about distributing enough intelligence out at the edge to calm the torrent of data, and change it from raw data over to real information that has value and gets forwarded up to the cloud.” Todd Baker, head of Cisco‘s IOx framework says. Fog Computing, which is somehow different from Edge Computing (we didn’t quite get how) is definitely a new business opportunity for the company who’s challenge is to package converged infrastructure services as products.
However, one interesting aspect of this new buzzword is that it adds up something new to the existing model: after all, cloud computing is based on the old client-server model, except the cloud is distributed by its nature (ahem, even though data is centralized). That’s the big difference. There’s a basic rule that resumes the IT’s industry race towards new solutions: Moore’s law. The industry’s three building blocks are: storage, computing and network. As computing power doubles every 18 months, storage follows closely (its exponential curve is almost similar). However, if we graph network growth it appears to follow a straight line.
Network capacity is a scarce resource, and it’s not going to change any time soon: it’s the backbone of the infrastructure, built piece by piece with colossal amounts of cables, routers and fiber optics. This problematic forces the industry to find disruptive solutions, and the paradigm arising from the clash between these growth rates now has a name: Data gravity.
Cookbook > Setting up your personal Linux & OwnCloud server
Note: would you like to install your personal open source cloud infrastructure, maintain it, manage your data by yourself and possibly develop artifacts upon it, like we needed to do in the frame of this project? If the answer is yes, then here comes below the step by step recipe on how to do it. The proposed software for Cloud-like operations, ownCloud, has been chosen among different ones. We explained our (interdisciplinary) choice in this post, commented here. It is an open source system with a wide community of developers (but no designers yet).
We plan to publish later some additional Processing libraries — in connection with this open source software — that will follow one of our research project’s objectives to help gain access to (cloud based) tools.
Would you then also like to “hide” your server in a traditional 19″ Cabinet (in your everyday physical or networked vicinity)? Here is a post that details this operation and what to possibly “learn” from it –”lessons” that will become useful when it will come to possible cabinet alternatives–.
Setting up our own (small size) personal cloud infrastructure. Part #3, reverse engineer the “black box”























At a very small scale and all things considered, a computer “cabinet” that hosts cloud servers and services is a very small data center and is in fact quite similar to large ones for its key components… (to anticipate the comments: we understand that these large ones are of course much more complex, more edgy and hard to “control”, more technical, etc., but again, not so fundamentally different from a conceptual point of view).
Documenting the black box… (or un-blackboxing it?)
You can definitely find similar concepts that are “scalable” between the very small – personal – and the extra large. Therefore the aim of this post, following two previous ones about software (part #1) –with a technical comment here– and hardware (part #2), is to continue document and “reverse engineer” the set up of our own (small size) cloud computing infrastructure and of what we consider as basic key “conceptual” elements of this infrastructure. The ones that we’ll possibly want to reassess and reassemble in a different way or question later during the I&IC research.
However, note that a meaningful difference between the big and the small data center would be that a small one could sit in your own house or small office, or physically find its place within an everyday situation (becoming some piece of mobile furniture? else?) and be administrated by yourself (becoming personal). Besides the fact that our infrastructure offers server-side computing capacities (therefore different than a Networked Attached Storage), this is also a reason why we’ve picked up this type of infrastructure and configuration to work with, instead of a third party API (i.e. Dropbox, Google Drive, etc.) with which we wouldn’t have access to the hardware parts. This system architecture could then possibly be “indefinitely” scaled up by getting connected to similar distant personal clouds in a highly decentralized architecture –like i.e. ownCloud seems now to allow, with its “server to server” sharing capabilities–.
See also the two mentioned related posts:
Setting up our own (small size) personal cloud infrastructure. Part #1, components
Setting up our own (small size) personal cloud infrastructure. Part #2, components
EIC / ECIA standards (for racks, cabinets, panels and associated equipment)
…
And now that the Electronic Industries Alliance (EIA) has become the Electronic Components Alliance (ECA) and has then merged with the National Electronic Distributors Association (NEDA), its new name is ECIA, standing for Electronic Components Industry Association. That’s where you can buy (for $88.00 usd) the norm EIA/ECA-310E that regulates the 19″ cabinets standard.
Acting like a building block, this modular standard ultimately gives shape to bigger size data centers that hold many of these racks and cabinets.
