By fabric | ch
—–
Along different projects we are undertaking at fabric | ch, we continue to work on self initiated researches and experiments (slowly, way too slowly… Time is of course missing). Deterritorialized House is one of them, introduced below.

Some of these experimental works concern the mutating “home” program (considered as “inhabited housing”), that is obviously an historical one for architecture but that is also rapidly changing “(…) under pressure of multiple forces –financial, environmental, technological, geopolitical. What we used to call home may not even exist anymore, having transmuted into a financial commodity measured in sqm (square meters)”, following Joseph Grima’s statement in sqm. the quantified home, “Home is the answer, but what is the question?”
In a different line of works, we are looking to build physical materializations in the form of small pavilions for projects like i.e. Satellite Daylight, 46°28′N, while other researches are about functions: based on live data feeds, how would you inhabit a transformed –almost geo-engineered atmospheric/environmental condition? Like the one of Deterritorialized Living (night doesn’t exist in this fictional climate that consists of only one day, no years, no months, no seasons), the physiological environment of I-Weather, or the one of Perpetual Tropical Sunshine, etc.?
We are therefore very interested to explore further into the ways you would inhabit such singular and “creolized” environments composed of combined dimensions, like some of the ones we’ve designed for installations. Yet considering these environments as proto-architecture (architectured/mediated atmospheres) and as conditions to inhabit, looking for their own logic.
We are looking forward to publish the results of these different projects along the year. Some as early sketches, some as results, or both. I publish below early sketches of such an experiment, Deterritorialized House, linked to the “home/house” line of research. It is about symbiotically inhabiting the data center… Would you like it or not, we surely de-facto inhabit it, as it is a globally spread program and infrastructure that surrounds us, but we are thinking here in physically inhabiting it, possibly making it a “home”, sharing it with the machines…
What is happening when you combine a fully deterritorialized program (super or hyper-modern, “non lieu”, …) with the one of the home? What might it say or comment about contemporary living? Could the symbiotic relation take advantage of the heat the machine are generating –directly connected to the amount of processing power used–, the quality of the air, the fact that the center must be up and running, possibly lit 24/7, etc.
As we’ll run a workshop next week in the context of another research project (Inhabiting and Interfacing the Cloud(s), an academic program between ECAL, HEAD, EPFL-ECAL Lab and EPFL in this case) linked to this idea of questioning the data center –its paradoxically centralized program, its location, its size, its functionalism, etc.–, it might be useful to publish these drawings, even so in their early phase (theys are dating back from early 2014, the project went back and forth from this point and we are still working on it.)
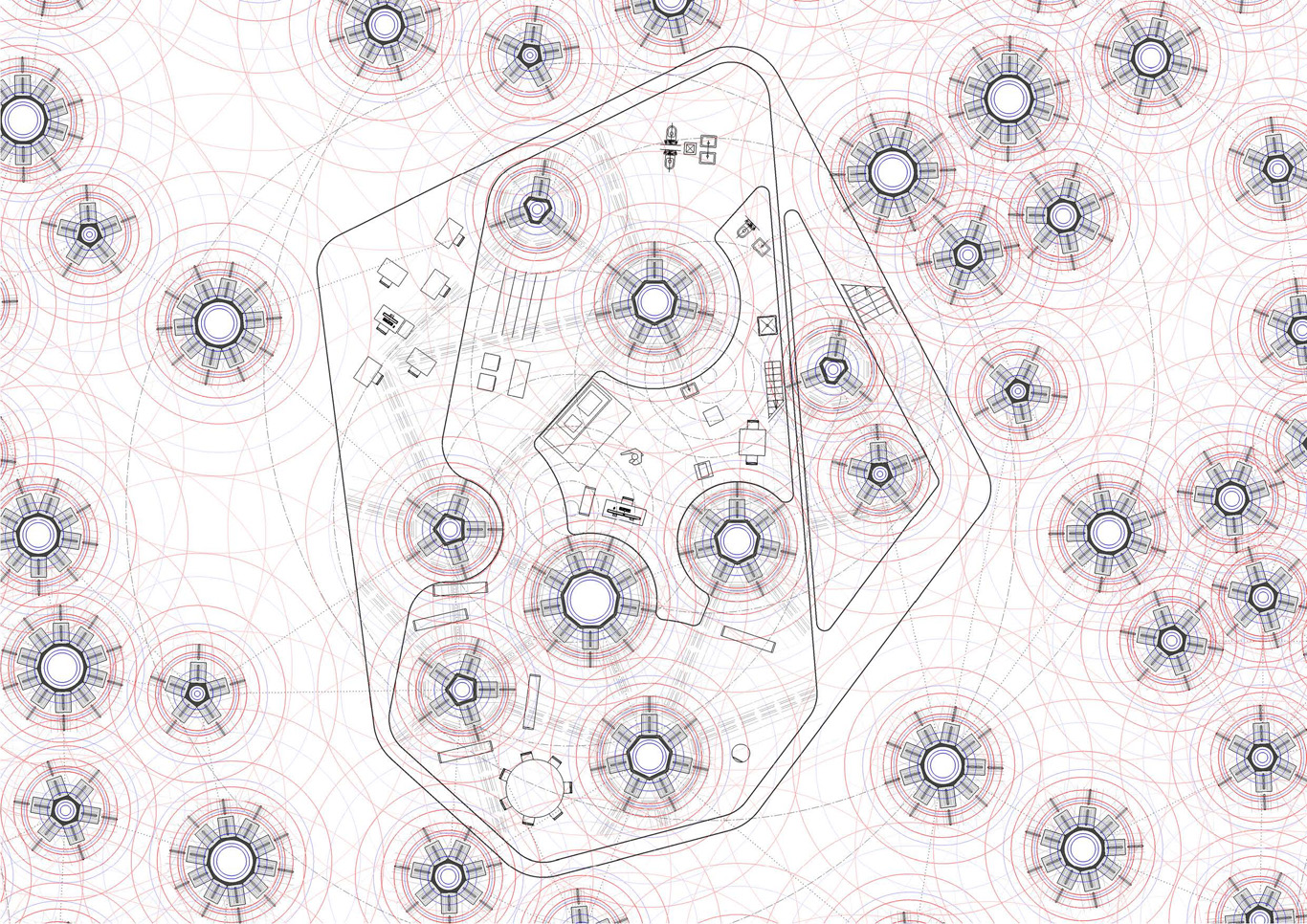
1) The data center level (level -1 or level +1) serves as a speculative territory and environment to inhabit (each circle in this drawing is a fresh air pipe sourrounded by a certain number of computers cabinets –between 3 and 9).
A potential and idealistic new “infinite monument” (global)? It still needs to be decided if it should be underground, cut from natural lighting or if it should be fragmented into many pieces and located in altitude (–likely, according to our other scenarios that are looking for decentralization and collaboration), etc. Both?
Fresh air is coming from the outside through the pipes surrounded by the servers and their cabinets (the incoming air could be an underground cooled one, or the one that can be found in altitude, in the Swiss Alps –triggering scenarios like cities in the moutains? moutain data farming? Likely too, as we are looking to bring data centers back into small or big urban environments). The computing and data storage units are organized like a “landscape”, trying to trigger different atmospheric qualities (some areas are hotter than others with the amount of hot air coming out of the data servers’ cabinets, some areas are charged in positive ions, air connectivity is obviously everywhere, etc.)
Artificial lighting follows a similar organization as the servers’ cabinets need to be well lit. Therefore a light pattern emerges as well in the data center level. Running 24/7, with the need to be always lit, the data center uses a very specific programmed lighting system: Deterritorialized Daylight linked to global online data flows.

2) Linked to the special atmospheric conditions found in this “geo-data engineered atmosphere” (the one of the data center itself, level -1 or 1), freely organized functions can be located according to their best matching location. There are no thick walls as the “cabinets islands” acts as semi-open partitions.
A program starts to appear that combines the needs of a data center and the one of a small housing program which is immersed into this “climate” (dense connectivity, always artificially lit, 24°C permanent heat). “Houses” start to appear as “plugs” into a larger data center.
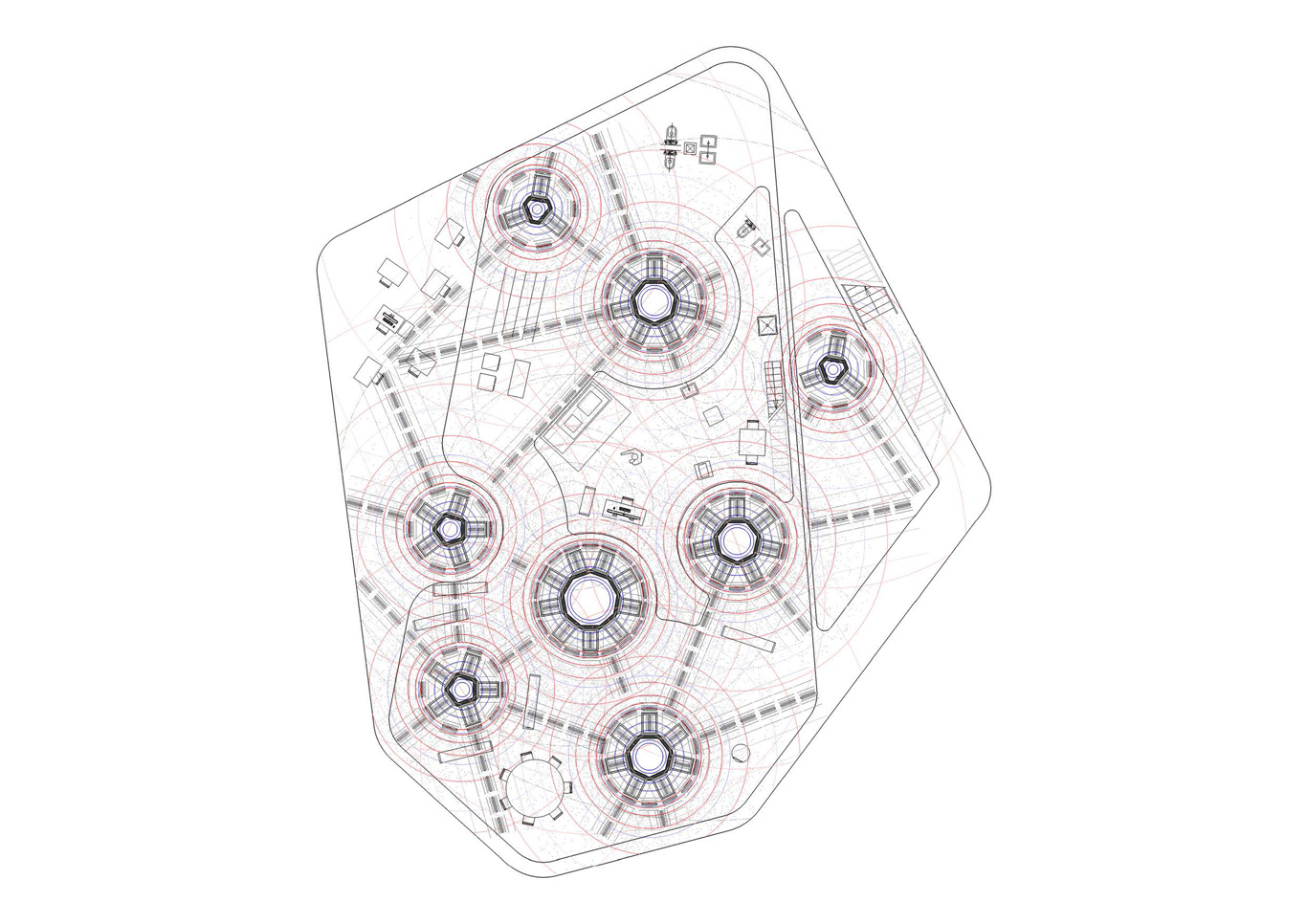
3) A detailed view (data center, level -1 or +1) on the “housing plug” that combine programs. At this level, the combination between an office-administration unit for a small size data center start to emerge, combined with a kind of “small office – home office” that is immersed into this perpetually lit data space. This specific small housing space (a studio, or a “small office – home office”) becomes a “deterritorialized” room within a larger housing program that we’ll find on the upper level(s), likely ground floor or level +2 of the overall compound.
4) Using the patterns emerging from different spatial components (heat, light, air quality –dried, charged in positive ions–, wifi connectivity), a map is traced and “moirés” patterns of spatial configurations (“moirés spaces”) start to happen. These define spatial qualities. Functions are “structurelessly” placed accordingly, on a “best matching location” basis (needs in heat, humidity, light, connectivity which connect this approach to the one of Philippe Rahm, initiated in a former research project, Form & Function Follow Climate (2006). Or also i.e. the one of Walter Henn, Burolandschaft (1963), if not the one of Junya Ishigami’s Kanagawa Institute).
Note also that this is a line of work that we are following in another experimental project at fabric | ch, about which we also hope to publish along the year, Algorithmic Atomized Functioning –a glimpse of which can be seen in Desierto Issue #3, 28° Celsius.
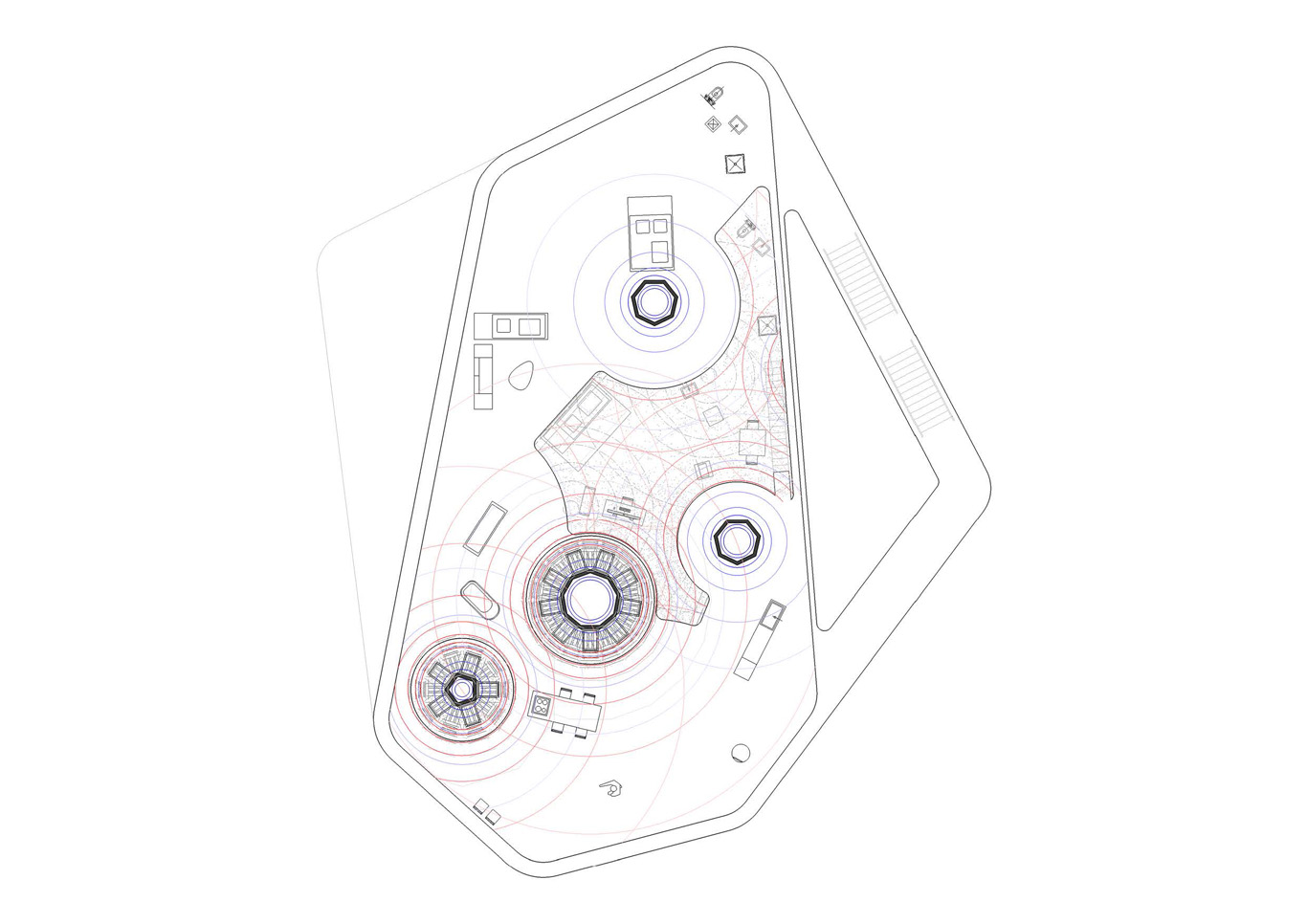
5) On ground level or on level +2, the rest of the larger house program and few parts of the data center that emerges. There are no other heating or artificial lighting devices besides the ones provided by the data center program itself. The energy spent by the data center must serve and somehow be spared by the house. Fresh and hot zones, artificial light and connectivity, etc. are provided by the data center emergences in the house, so has from the opened “small office – home office” that is located one floor below. Again, a map is traced based and moirés patterns of specific locations and spatial configurations emerge. Functions are also placed accordingly (hot, cold, lit, connected zones).
Starts or tries to appear a “creolized” housing object, somewhere in between a symbiotic fragmented data center and a house, possibly sustaining or triggering new inhabiting patterns…