Note: When we had to pick an open source cloud computing platform at the start of our research, we dug for some time to pick the one that would better match with our planned activities. We chose ownCloud and explained our choice in a previous post, so as some identified limitations linked to it. Early this year came this announcement by ownCloud that it will initiate “Global Interconnected Private Clouds for Universities and Researchers” (with early participants such has the CERN, ETHZ, SWITCH, TU-Berlin, University of Florida, University of Vienna, etc.) So it looks like we’ve picked the right open platform! Especially also because they are announcing a mesh layer on top of different clouds to provide common access across globally interconnected organizations.
This comforts us in our initial choice and the need to bridge it with the design community, especially as this new “mesh layer” is added to ownCloud, which was something missing when we started this project (from ownCloud version 7.0, this scalability became available though). It now certainly allows what we were looking for: a network of small and personal data centers. Now the question comes back to design: if personal data centers are not big undisclosed or distant facilities anymore, how could they look like? For what type of uses? If the personal applications are not “file sharing only” oriented, what could they become? For what kind of scenarios?
By ownCloud
ownCloud Initiates Global Interconnected Private Clouds for Universities and Researchers
Leading research organizations in the Americas, Europe and Asia/Pacific join to create world’s largest public private cloud mesh.
Lexington, MA – January 29, 2015 – ownCloud, Inc., the company behind the world’s most popular open source file sync and share software, today announced an ambitious project that for the first time ties together researchers and universities in the Americas, Europe and Asia via a series of interconnected, secure private clouds.
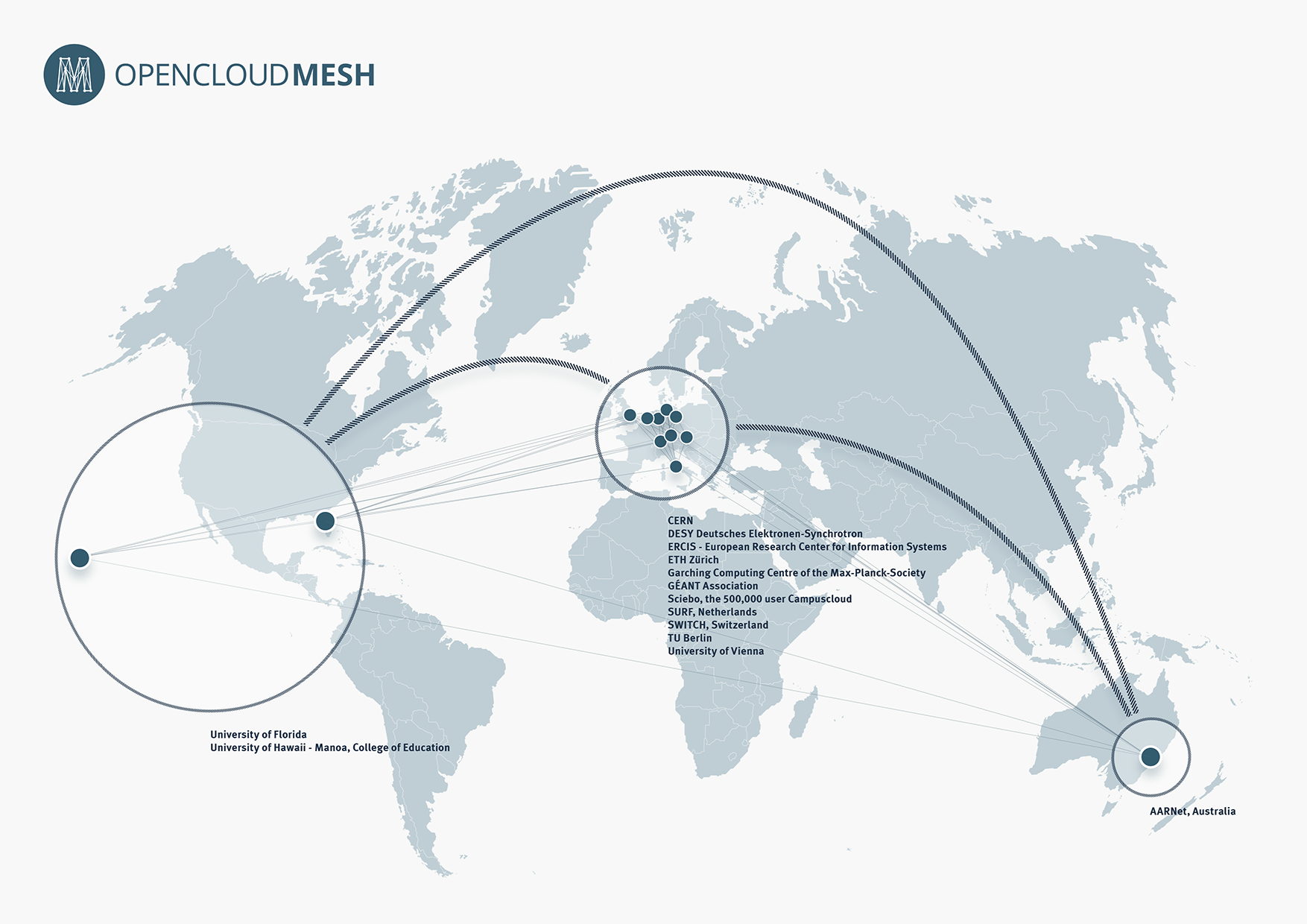
OpenCloudMesh, a joint international initiative under the umbrella of the GÉANT Association, is built on ownCloud’s open Federated Cloud sharing application programming interface (API) taking Universal File Access beyond the borders of individual Clouds and into a globally interconnected mesh of research clouds — without sacrificing any of the advantages in privacy, control and security an on-premises cloud provides. OpenCloudMesh provides a common file access layer across an organization and across globally interconnected organizations, whether the data resides on internal servers, on object storage, in applications like SharePoint or Jive, other ownClouds, or even external cloud systems such as Dropbox and Google (syncing them to desktops or mobile apps, making them available offline).
“Research labs and universities are by nature social institutions – collaborating, communicating and testing — but at the same time these same institutions must be very protective of their students, researchers and research. This often puts them at the cutting edge of technology,” said Frank Karlitschek, CTO, and co-founder, ownCloud. “OpenCloudMesh gives each organization private cloud file sync and share, while Federated Cloud sharing, also known as server-to-server sharing, enables safe sharing between those clouds. The possibilities are unlimited not just for researchers and universities, but for enterprises large and small as well.”
“We are at a critical juncture in cloud computing,” said Peter Szegedi Project Development Officer, Management Team, GÉANT Association. “There is no longer a need to choose between privacy and security and collaboration and ease of use. We believe OpenCloudMesh will redefine the way people use the cloud to share their important files.”
This open API ensures secure yet transparent connections between remote on-premises cloud installations. A first draft of this OpenCloudMesh API specification will be published early this year and participation in developing and refining the API is open to all.
To-date, 14 organizations have signed up to participate, including:
- CERN
- Sciebo , the 500k user Campuscloud
- University of Florida
- SWITCH
- SURF
- University of Hawaii – Manoa, College of Education
- University of Vienna
- AARNet
- Garching Computing Centre of the Max-Planck-Society
- GÉANT Association
- DESY Deutsches Elektronen-Synchrotron
- ETH Zürich
- ERCIS – European Research Center for Information Systems
- TU Berlin
Get Involved
For more information, or for researchers and universities interested in getting involved please visit https://owncloud.com/opencloudmesh/.
ownCloud protects sensitive corporate files, while providing end users with flexible and easy access to files, from any device, anywhere. Federated Cloud sharing enables users on one ownCloud installation to seamlessly share files with users on a different ownCloud installation without using shared links. Both users retain the privacy and control of a private ownCloud, and gain the flexibility and ease-of-use of a public cloud.
About GÉANT Association
GÉANT is the pan-European research and education network that interconnects Europe’s National Research and Education Networks (NRENs). Together we connect over 50 million users at 10,000 institutions across Europe, supporting research in areas such as energy, the environment, space and medicine.
About ownCloud, Inc.
Based on the popular ownCloud open source file sync and share community project, ownCloud Inc. was founded in 2011 to give corporate IT greater control of their data and files — providing a common file access layer across an organization, enabling file access from any device, anytime, from anywhere, all completely managed and controlled by IT. Company headquarters are in Lexington, MA, with European headquarters in Nuremberg, Germany. For more information, visit: http://www.owncloud.com.