IICloud(s) – Inhabiting and Interfacing the Cloud(s)
A joint design research project (HES-SO) between ECAL, HEAD, EPFL-ECAL Lab & EPFL
-
-
A few images for a brief history (of computing) time
Note: a aet of images I’ll need for a short introduction to the project.
From mainframe computers to cloud computing, through personal computer and all other initiatives that tried to curve “the way computers go” and provide access to tools to people who were not necessarily computer savvy. Under this perspective (“access to tools”), cloud computing is a new paradigm that takes us away from that of the personal computer. To the point that it brings us back to the time of the mainframe computer (no-access or difficult access to tools)?
If we consider how far the personal computer, combined with the more recent Internet, has changed the ways we interact, work and live, we should certainly pay attention to this new paradigm that is coming and probably work hard to make it “accessible”.

A very short history pdf in 14 images.
-
Reblog > Deterritorialized House – Inhabiting the data center, sketches…
By fabric | ch
—–
Along different projects we are undertaking at fabric | ch, we continue to work on self initiated researches and experiments (slowly, way too slowly… Time is of course missing). Deterritorialized House is one of them, introduced below.

-
Reblog > Decentralizing the Cloud: How Can Small Data Centers Cooperate?
Note: while reading last Autumn newsletter from our scientific committee partner Ecocloud (EPFL), among the many interesting papers the center is publishing, I stumbled upon this one written by researchers Hao Zhuang, Rameez Rahman, and Prof. Karl Aberer. It surprised me how their technological goals linked to decentralization seem to question similar issues as our design ones (decentralization, small and networked data centers, privacy, peer to peer models, etc.)! Yet not in such a small size as ours, which rather look toward the “personal/small” and “maker community” size. They are rather investigating “regional” data centers, which is considered small when you start talking about data centers.
-
Inhabiting and Interfacing the Cloud(s) – Talk & workshop at LIFT 15
Note: Nicolas Nova and I will be present during next Lift Conference in Geneva (Feb. 4-6 2015) for a talk combined with a workshop and a skype session with EPFL (a workshop related with the I&IC research project will be finishing at EPFL –Prof. Dieter Dietz’s ALICE Laboratory at EPFL-ECAL Lab– the day we’ll present in Geneva). All persons who follow the research on this blog and that would be present during Lift 15, please come see us and exchange ideas!
Via the Lift Conference
—–
Inhabiting and Interfacing the Cloud(s)
WorkshopCurated by LiftFri, Feb. 06 2015 – 10:30 to 12:30Room 7+8 (Level 2)- Architect (EPFL), founding member of fabric | ch and Professor at ECAL-
Architect (EPFL), founding member of fabric | ch and Professor at ECAL- Principal at Near Future Laboratory and Professor at HEAD Geneva-
Principal at Near Future Laboratory and Professor at HEAD Geneva-Workshop description : Since the end of the 20th century, we have been seeing the rapid emergence of “Cloud Computing”, a new constructed entity that combines extensively information technologies, massive storage of individual or collective data, distributed computational power, distributed access interfaces, security and functionalism.
In a joint design research that connects the works of interaction designers from ECAL & HEAD with the spatial and territorial approaches of architects from EPFL, we’re interested in exploring the creation of alternatives to the current expression of “Cloud Computing”, particularly in its forms intended for private individuals and end users (“Personal Cloud”). It is to offer a critical appraisal of this “iconic” infrastructure of our modern age and its user interfaces, because to date their implementation has followed a logic chiefly of technical development, governed by the commercial interests of large corporations, and continues to be seen partly as a purely functional,centralized setup. However, the Personal Cloud holds a potential that is largely untapped in terms of design, novel uses and territorial strategies.
The workshop will be an opportunity to discuss these alternatives and work on potential scenarios for the near future. More specifically, we will address the following topics:
- How to combine the material part with the immaterial, mediatized part? Can we imagine the geographical fragmentation of these setups?
- Might new interfaces with access to ubiquitous data be envisioned that take nomadic lifestyles into account and let us offer alternatives to approaches based on a “universal” design? Might these interfaces also partake of some kind of repossession of the data by the end users?
- What setups and new combinations of functions need devising for a partly nomadic lifestyle? Can the Cloud/Data Center itself be mobile?
- Might symbioses also be developed at the energy and climate levels (e.g. using the need to cool the machines, which themselves produce heat, in order to develop living strategies there)? If so, with what users (humans, animals, plants)?
The joint design research Inhabiting & Interfacing the Cloud(s) is supported by HES-SO, ECAL & HEAD.
Interactivity : The workshop will start with a general introduction about the project, and moves to a discussion of its implications, opportunities and limits. Then a series of activities will enable break-out groups to sketch potential solutions.
-
Moving clouds: International transportation standards

As a technical starting point of this research Patrick Keller already wrote two posts on hardware standards and measures: The Rack Unit and the EIC /ECIA Standards (other articles including technical overview are the 19 Inch Rack & Rack Mount Cases). Within the same intent of understanding the technical standards and limitations that shape the topologies of data centers we decided to investigate how the racks can be packed, shipped, and gain mobility. The standards for server transportation safety are set by the Rack Transport Stability Team (RTST) guidelines. Of course, custom built server packaging exists based on the international standards. We’ll start by listing them from the smallest to the biggest dimensions. First off, the pallet is the smallest measure. Once installed on pallets, the racks can be disposed in standard 20′ or 40′ shipping containers. The image below depicts different ways of arranging the pallets within the container:
-
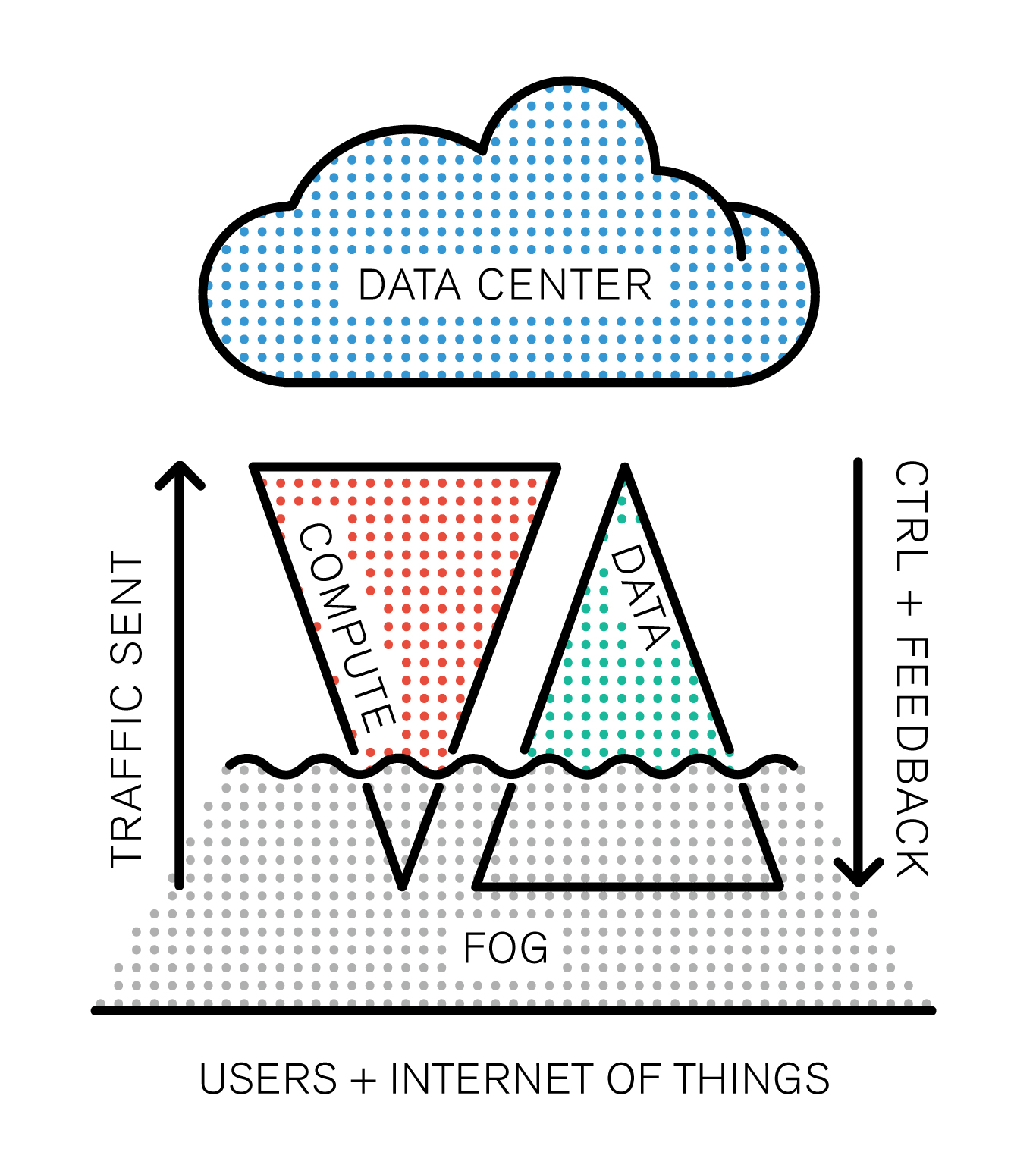
Towards a new paradigm: Fog Computing
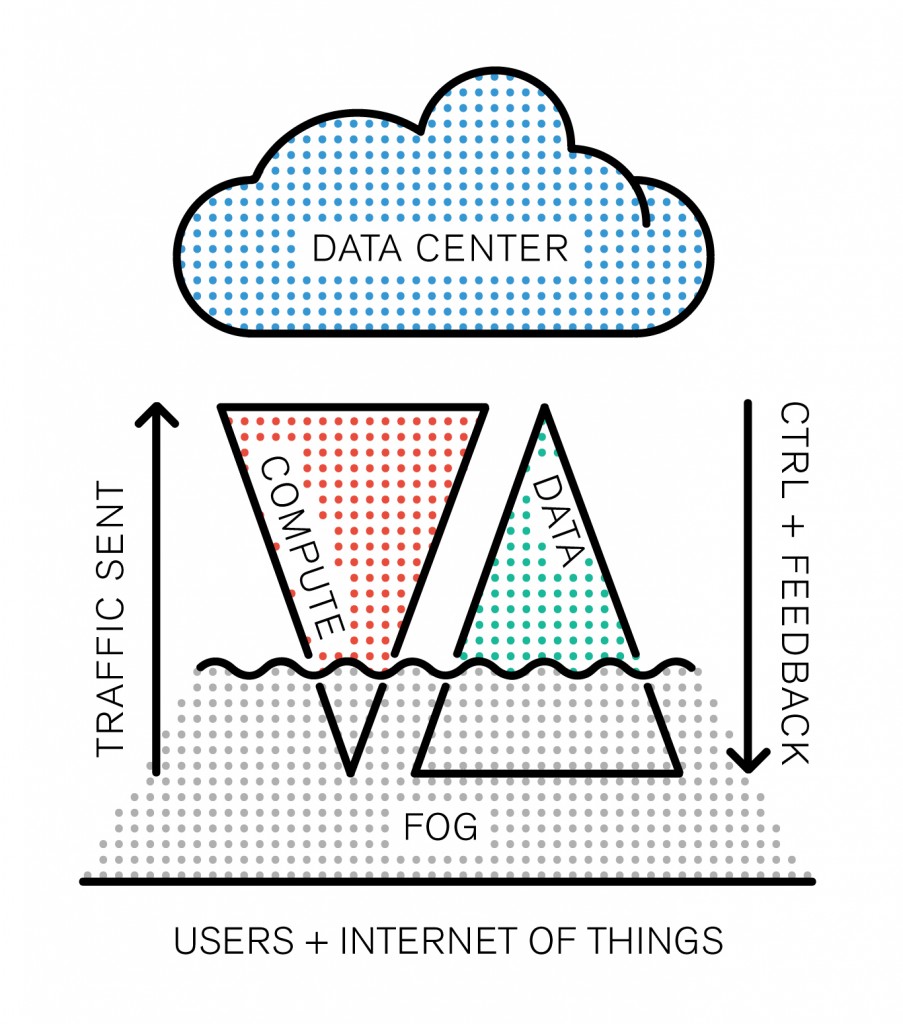
The Internet of Things is emerging as a model, and the network routing all the IoT data to the cloud is at risk of getting clogged up. “Fog is about distributing enough intelligence out at the edge to calm the torrent of data, and change it from raw data over to real information that has value and gets forwarded up to the cloud.” Todd Baker, head of Cisco‘s IOx framework says. Fog Computing, which is somehow different from Edge Computing (we didn’t quite get how) is definitely a new business opportunity for the company who’s challenge is to package converged infrastructure services as products.
However, one interesting aspect of this new buzzword is that it adds up something new to the existing model: after all, cloud computing is based on the old client-server model, except the cloud is distributed by its nature (ahem, even though data is centralized). That’s the big difference. There’s a basic rule that resumes the IT’s industry race towards new solutions: Moore’s law. The industry’s three building blocks are: storage, computing and network. As computing power doubles every 18 months, storage follows closely (its exponential curve is almost similar). However, if we graph network growth it appears to follow a straight line.
Network capacity is a scarce resource, and it’s not going to change any time soon: it’s the backbone of the infrastructure, built piece by piece with colossal amounts of cables, routers and fiber optics. This problematic forces the industry to find disruptive solutions, and the paradigm arising from the clash between these growth rates now has a name: Data gravity.
-
Cookbook > Setting up your personal Linux & OwnCloud server
Note: would you like to install your personal open source cloud infrastructure, maintain it, manage your data by yourself and possibly develop artifacts upon it, like we needed to do in the frame of this project? If the answer is yes, then here comes below the step by step recipe on how to do it. The proposed software for Cloud-like operations, ownCloud, has been chosen among different ones. We explained our (interdisciplinary) choice in this post, commented here. It is an open source system with a wide community of developers (but no designers yet).
We plan to publish later some additional Processing libraries — in connection with this open source software — that will follow one of our research project’s objectives to help gain access to (cloud based) tools.
Would you then also like to “hide” your server in a traditional 19″ Cabinet (in your everyday physical or networked vicinity)? Here is a post that details this operation and what to possibly “learn” from it –”lessons” that will become useful when it will come to possible cabinet alternatives–.
-
Setting up our own (small size) personal cloud infrastructure. Part #3, reverse engineer the “black box”























At a very small scale and all things considered, a computer “cabinet” that hosts cloud servers and services is a very small data center and is in fact quite similar to large ones for its key components… (to anticipate the comments: we understand that these large ones are of course much more complex, more edgy and hard to “control”, more technical, etc., but again, not so fundamentally different from a conceptual point of view).

Documenting the black box… (or un-blackboxing it?)
You can definitely find similar concepts that are “scalable” between the very small – personal – and the extra large. Therefore the aim of this post, following two previous ones about software (part #1) –with a technical comment here– and hardware (part #2), is to continue document and “reverse engineer” the set up of our own (small size) cloud computing infrastructure and of what we consider as basic key “conceptual” elements of this infrastructure. The ones that we’ll possibly want to reassess and reassemble in a different way or question later during the I&IC research.
However, note that a meaningful difference between the big and the small data center would be that a small one could sit in your own house or small office, or physically find its place within an everyday situation (becoming some piece of mobile furniture? else?) and be administrated by yourself (becoming personal). Besides the fact that our infrastructure offers server-side computing capacities (therefore different than a Networked Attached Storage), this is also a reason why we’ve picked up this type of infrastructure and configuration to work with, instead of a third party API (i.e. Dropbox, Google Drive, etc.) with which we wouldn’t have access to the hardware parts. This system architecture could then possibly be “indefinitely” scaled up by getting connected to similar distant personal clouds in a highly decentralized architecture –like i.e. ownCloud seems now to allow, with its “server to server” sharing capabilities–.
See also the two mentioned related posts:
Setting up our own (small size) personal cloud infrastructure. Part #1, components
Setting up our own (small size) personal cloud infrastructure. Part #2, components
-
EIC / ECIA standards (for racks, cabinets, panels and associated equipment)
…
And now that the Electronic Industries Alliance (EIA) has become the Electronic Components Alliance (ECA) and has then merged with the National Electronic Distributors Association (NEDA), its new name is ECIA, standing for Electronic Components Industry Association. That’s where you can buy (for $88.00 usd) the norm EIA/ECA-310E that regulates the 19″ cabinets standard.
Acting like a building block, this modular standard ultimately gives shape to bigger size data centers that hold many of these racks and cabinets.
-
Virtualization
Virtualization, in computing, refers to the act of creating a virtual (rather than actual) version of something, including but not limited to a virtual computer hardware platform, operating system (OS), storage device, or computer network resources.
Virtualization began in 1960s mainframe computers as a method of logically dividing the mainframes’ resources for different applications. Since then, the meaning of the term has broadened.[1]
… it continued and now this concept and technology is widely used to set up system architecture within data centers. Virtualized (data) servers populate physical servers. A well known company that is specialized around these questions is VMware.
-
“Botcaves” on #algopop
Matthew Plummer-Fernandez just took the occasion to publish the results of the workshop he led at ECAL on #algopop (“studying the appearance of algorithms in popular culture and everyday life”)!
-
Data Hotel

(Reblogged from Pasta and Vinegar)
A billboard encountered at Haneda Airport in Tokyo this week. I find it interesting to observe the criteria chosen by the cloud company: we understand here that the service should be easy and that a reliable support might exist (24 hours). This looks quite common in the tech industry. However, I find the two others characteristics quite intriguing: “public cloud” and “system architect” sounds a bit abstract and strange. Perhaps the latter corresponds to the idea of a well-designed system, but I wonder about the notion of “public cloud” itself: what does that mean? Although it might suggest a public access to data, it may consist in something else (perhaps there’s a Japanese thing I’m missing here) as it’s difficult to sell people a service where all your data are made public.
-
I&IC Workshop #3 with Algopop at ECAL: output > “Botcaves” / Networked Data Objects
Note: the post I&IC Workshop #3 with Algopop at ECAL, brief: “Botcaves” presents the objectives and brief for this workshop.
The third workshop we ran in the frame of I&IC with our guest researcher Matthew Plummer-Fernandez (Goldsmiths University) and the 2nd & 3rd year students (Ba) in Media & Interaction Design (ECAL) ended last Friday with interesting results. The workshop focused on small situated computing technologies that could collect, aggregate and/or “manipulate” data in automated ways (bots) and which would certainly need to heavily rely on cloud technologies due to their low storage and computing capacities. So to say “networked data objects” that will soon become very common, thanks to cheap new small computing devices (i.e. Raspberry Pis for diy applications) or sensors (i.e. Arduino, etc.) The title of the workshop was “Botcave”, which objective was explained by Matthew in a previous post.
Botcaves – a workshop with Matthew Plummer-Fernandez at ECAL on Vimeo.
The choice of this context of work was defined accordingly to our overall research objective, even though we knew that it wouldn’t address directly the “cloud computing” apparatus — something we learned to be a difficult approach during the second workshop –, but that it would nonetheless question its interfaces and the way we experience the whole service. Especially the evolution of this apparatus through new types of everyday interactions and data generation.

Matthew Plummer-Fernandez (#Algopop) during the final presentation at the end of the research workshop.
Through this workshop, Matthew and the students definitely raised the following points and questions (details about the projects are below):
1° Small situated technologies that will soon spread everywhere will become heavy users of cloud based computing and data storage, as they have low storage and computing capacities. While they might just use and manipulate existing data (like some of the workshop projects — i.e. #Good vs. #Evil or Moody Printer) they will altogether and mainly also contribute to produce extra large additional quantities of them (i.e. Robinson Miner). Yet, the amount of meaningful data to be “pushed” and “treated” in the cloud remains a big question mark, as there will be (too) huge amounts of such data –Lucien will probably post something later about this subject: “fog computing“–, this might end up with the need for interdisciplinary teams to rethink cloud architectures.
2° Stored data are becoming “alive” or significant only when “manipulated”. It can be done by “analog users” of course, but in general it is now rather operated by rules and algorithms of different sorts (in the frame of this workshop: automated bots). Are these rules “situated” as well and possibly context aware (context intelligent) –i.e. Robinson Miner? Or are they somehow more abstract and located anywhere in the cloud? Both?
3° These “Networked Data Objects” (and soon “Network Data Everything”) will contribute to “babelize” users interactions and interfaces in all directions, paving the way for new types of combinations and experiences (creolization processes) — i.e. The Beast, The Like Hotline, Simon Coins, The Wifi Cracker could be considered as starting phases of such processes–. Cloud interfaces and computing will then become everyday “things” and when at “house”, new domestic objects with which we’ll have totally different interactions (this last point must still be discussed though as domesticity might not exist anymore according to Space Caviar).
Moody Printer – (Alexia Léchot, Benjamin Botros)

Moody Printer remains a basic conceptual proposal at this stage, where a hacked printer, connected to a Raspberry Pi that stays hidden (it would be located inside the printer), has access to weather information. Similarly to human beings, its “mood” can be affected by such inputs following some basic rules (good – bad, hot – cold, sunny – cloudy -rainy, etc.) The automated process then search for Google images according to its defined “mood” (direct link between “mood”, weather conditions and exhaustive list of words) and then autonomously start to print them.
A different kind of printer combined with weather monitoring.
The Beast – (Nicolas Nahornyj)


Top: Nicolas Nahornyj is presenting his project to the assembly. Bottom: the laptop and “the beast”.
The Beast is a device that asks to be fed with money at random times… It is your new laptop companion. To calm it down for a while, you must insert a coin in the slot provided for that purpose. If you don’t comply, not only will it continue to ask for money in a more frequent basis, but it will also randomly pick up an image that lie around on your hard drive, post it on a popular social network (i.e. Facebook, Pinterest, etc.) and then erase this image on your local disk. Slowly, The Beast will remove all images from your hard drive and post them online…
A different kind of slot machine combined with private files stealing.
Robinson – (Anne-Sophie Bazard, Jonas Lacôte, Pierre-Xavier Puissant)


Top: Pierre-Xavier Puissant is looking at the autonomous “minecrafting” of his bot. Bottom: the proposed bot container that take on the idea of cubic construction. It could be placed in your garden, in one of your room, then in your fridge, etc.
Robinson automates the procedural construction of MineCraft environments. To do so, the bot uses local weather information that is monitored by a weather sensor located inside the cubic box, attached to a Raspberry Pi located within the box as well. This sensor is looking for changes in temperature, humidity, etc. that then serve to change the building blocks and rules of constructions inside MineCraft (put your cube inside your fridge and it will start to build icy blocks, put it in a wet environment and it will construct with grass, etc.)
A different kind of thermometer combined with a construction game.
Note: Matthew Plummer-Fernandez also produced two (auto)MineCraft bots during the week of workshop. The first one is building environment according to fluctuations in the course of different market indexes while the second one is trying to build “shapes” to escape this first envirnment. These two bots are downloadable from the Github repository that was realized during the workshop.
#Good vs. #Evil – (Maxime Castelli)


Top: a transformed car racing game. Bottom: a race is going on between two Twitter hashtags, materialized by two cars.
#Good vs. #Evil is a quite straightforward project. It is also a hack of an existing two racing cars game. Yet in this case, the bot is counting iterations of two hashtags on Twitter: #Good and #Evil. At each new iteration of one or the other word, the device gives an electric input to its associated car. The result is a slow and perpetual race car between “good” and “evil” through their online hashtags iterations.
A different kind of data visualization combined with racing cars.
The “Like” Hotline – (Mylène Dreyer, Caroline Buttet, Guillaume Cerdeira)


Top: Caroline Buttet and Mylène Dreyer are explaining their project. The screen of the laptop, which is a Facebook account is beamed on the left outer part of the image. Bottom: Caroline Buttet is using a hacked phone to “like” pages.
The “Like” Hotline is proposing to hack a regular phone and install a hotline bot on it. Connected to its online Facebook account that follows a few personalities and the posts they are making, the bot ask questions to the interlocutor which can then be answered by using the keypad on the phone. After navigating through a few choices, the bot hotline help you like a post on the social network.
A different kind of hotline combined with a social network.
Simoncoin – (Romain Cazier)


Top: Romain Cazier introducing its “coin” project. Bottom: the device combines an old “Simon” memory game with the production of digital coins.
Simoncoin was unfortunately not functional at the end of the week of workshop but was thought out in force details that would be too long to explain in this short presentation. Yet the main idea was to use the game logic of the famous Simon says to generate coins. In a parallel approach to the one of the Bitcoins that are harder and harder to mill, Simoncoins are also more and more difficult to generate due to the inner game logic: each time a level is achieved by a user on the physical installation, a coin is generated and made available to him in the cloud (so as a tweet that says a coin has been generated). The main difference being that it is not the power of the machine that matters, but its user’s ability.
Another different kind of money combined with a game.
The Wifi Oracle - (Bastien Girshig, Martin Hertig)



Top: Bastien Girshig and Martin Hertig (left of Matthew Plummer-Fernandez) presenting. Middle and Bottom: the wifi password cracker slowly diplays the letters of the wifi password.
The Wifi Oracle is an object that you can independently leave in a space. It furtively looks a little bit like a clock, but it won’t display time. Instead, it will look for available wifi networks in the area and start try to crack their protected password (Bastien and Martin found online a ready made process for that). Installed on the Raspberry Pi inside the Oracle, the bot will test all possible combinations and it will take the necessary time do do so. Once the device will have found the working password, it will use its round display to display it within the space it has been left in. Letter by letter and in a slow manner as well.
A different kind of cookoo clock combined with a password cracker.
Acknowledgments:
Lots of thanks to Matthew Plummer-Fernandez for its involvement and great workshop direction; Lucien Langton for its involvment, technical digging into Raspberry Pis, pictures and documentation; Nicolas Nova and Charles Chalas (from HEAD) so as Christophe Guignard, Christian Babski and Alain Bellet for taking part or helping during the final presentation. A special thanks to the students from ECAL involved in the project and the energy they’ve put into it: Anne-Sophie Bazard, Benjamin Botros, Maxime Castelli, Romain Cazier, Guillaume Cerdeira, Mylène Dreyer, Bastien Girshig, Martin Hertig, Jonas Lacôte, Alexia Léchot, Nicolas Nahornyj, Pierre-Xavier Puissant.

From left to right: Bastien Girshig, Martin Hertig (The Wifi Cracker project), Nicolas Nova, Matthew Plummer-Fernandez (#Algopop), a “mystery girl”, Christian Babski (in the background), Patrick Keller, Sebastian Vargas, Pierre Xavier-Puissant (Robinson Miner), Alain Bellet and Lucien Langton (taking the pictures…) during the final presentation on Friday.
-
I&IC Workshop #3 with Algopop at ECAL: The birth of Botcaves

The Bots are running! The second workshop of I&IC’s research study started yesterday with Matthew’s presentation to the students. A video of the presentation might be included in the post later on, but for now here’s the [pdf]: Botcaves
First prototypes setup by the students include bots playing Minecraft, bots cracking wifi’s, bots triggered by onboard IR Cameras. So far, some groups worked directly with Python scripts deployed via SSH into the Pi’s, others established a client-server connection between their Mac and their Pi by installing Processing on their Raspberry and finally some decided to start by hacking hardware to connect to their bots later.
The research process will be continuously documented during the week.